By now, the operational method is clear. Stop asking frontline teams to perform due diligence under time pressure. Move the burden of proof back to the requester. Protect frontline decisions by recording why a request was approved or denied, not just the outcome. Classify proof into identity, representation, and authorization so people stop guessing.
On paper, the method is sound. The problem is where it has to operate.
In freight, proof does not live in one place. It’s scattered across companies, systems, inboxes, and moments in time. Authorization might exist in an email thread. Representation might live in an onboarding file. Identity might be inferred from past interactions. None of it reliably converges where execution actually happens.
Frontline operators are asked to apply a method that depends on proof, but are rarely given access to that proof at the moment a decision has to be made. When that happens, there are only two options. Either work stops entirely, or proof is reconstructed manually under pressure.
In practice, reconstruction always wins. And that’s how the method collapses.
Consider a mid-load reroute. Earlier in the day, a broker and shipper agree to a change. That authorization exists — but it lives in a private email thread between those parties. Later, the carrier dispatcher calls the driver and instructs them to reroute.
This is a contractual change. It requires authorization from the shipper. The authorization is real. The problem is that the driver has no access to it. They can’t see the broker–shipper conversation. They can’t verify scope or timing. They can’t tell whether the dispatcher is relaying approved instruction or simply issuing one.
So the driver faces a choice. Refuse to execute and stop the load, or trust the dispatcher’s word. Trust wins.
What collapses here isn’t policy. It’s reach. Authorization existed, but it couldn’t reach execution. Once that happens, proof degrades into hierarchy and familiarity. A contractual decision gets made without verifiable authorization, not because approval didn’t exist, but because it couldn’t travel.
The same pattern appears with representation. A carrier dispatcher contacts broker ops and says, “I’m taking over this load — no other changes.” This binds the carrier organization. Representation needs to be established.
Proof of representation exists somewhere. In onboarding records. In HR systems. In historical relationships. But none of it is current, authoritative, or visible to broker ops during the call. What is visible is continuity: a familiar email domain, a known name, the fact that the conversation seems to follow from earlier messages.
Those signals substitute for proof. A real person now acts with assumed company authority. Representation is inferred, not verified — not because the broker ignored procedure, but because the system gave them nothing better to work with.
Even identity failures follow the same logic. A loosely verified external party asks for a status update: load status, ETA, delivery timing. The request feels harmless. Partial identity signals check out. The language is plausible. The timing makes sense.
Information is shared casually. No immediate harm occurs. But reconnaissance is completed. That information later enables representation claims, authorization requests, and time-sensitive pressure. Identity failure doesn’t move freight. It prepares the ground.
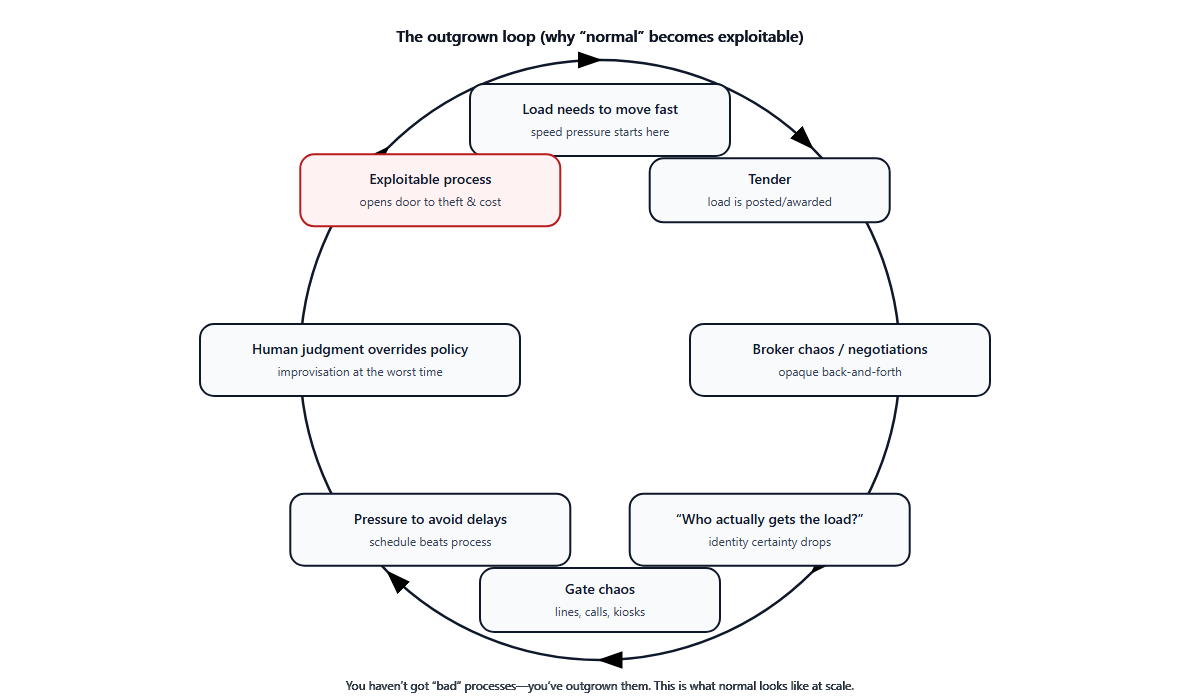
Across all three scenarios, the pattern is the same. Proof exists. Proof is distributed. Proof is inaccessible at the moment of decision. So frontline operators compensate the only way humans can: by trusting hierarchy, relying on familiarity, inferring intent, and making judgment calls anyway.
Due diligence reappears exactly where the method said it must not. Not because people ignored the method, but because the method had nowhere to live.
This isn’t a training problem. It isn’t a discipline problem. It isn’t a vigilance problem. The method fails because proof cannot cross company and system boundaries fast enough to reach execution. When proof can’t arrive, humans are forced to guess. And once guessing returns, the first principle is violated: frontline teams are again performing due diligence under pressure.
That leads to an unavoidable conclusion. Any system meant to support this method has to meet two hard requirements.
First, proof has to be tied to a specific load. Identity, representation, and authorization can’t exist as generic credentials or standing permissions. They have to be scoped to a particular load, valid for a particular moment, and reviewable in context. If proof floats independently of execution, it will never reach the frontline intact.
Second, proof has to reach the decision-maker without leaking information. Frontline operators need to be able to verify that authorization exists, that it came from the correct party, and that it applies to this request. What they must not be exposed to is who approved, how approval was obtained, or which internal relationships can be exploited later.
Knowing that approval exists is necessary. Knowing who approved is often harmful. Any system that reveals approver identity to the wrong party creates new attack surface instead of reducing it.
When proof leaks context, responsibility drifts back to individuals. Social engineering becomes easier. Future attacks gain leverage. When proof is properly scoped and abstracted, frontline teams can act without guessing, responsibility stays with the requester, and decisions remain defensible even under pressure.
That is the difference between verifying authority and reconstructing trust.
A simple test follows from this. If a system requires frontline teams to infer intent, recognize names, judge credibility, or decide whether approval “sounds right,” it has failed the method. Not because it’s poorly built, but because it violates the first principle it was meant to support.
The next entries will focus on how teams actually meet these requirements in practice: how proof is requested, how it’s scoped, and how it reaches execution without leaking context. Not as features, but as operational patterns that make this method hold when pressure returns.